
Hi, I'm Ruizhe Wang (王瑞哲) 👋, currently pursuing a joint Ph.D. program between USTC and Microsoft Research Asia, co-supervised by Prof. Zhengjun Zha and Prof. Baining Guo. I also collaborate closely with Peng Cheng and Yeyun Gong at MSRA.
My research interest are AI Infrastructure, Large Language Model (LLM) Pretraining, and Efficient AI System Designing. I enjoy building scalable models, exploring novel training methods, and solving challenging problems at the intersection of theory and practice.
I’m looking to collaborate on inspirable companions. You can find more info related to my research on my google scholar homepage: 
📖 Educations
📝 Publications
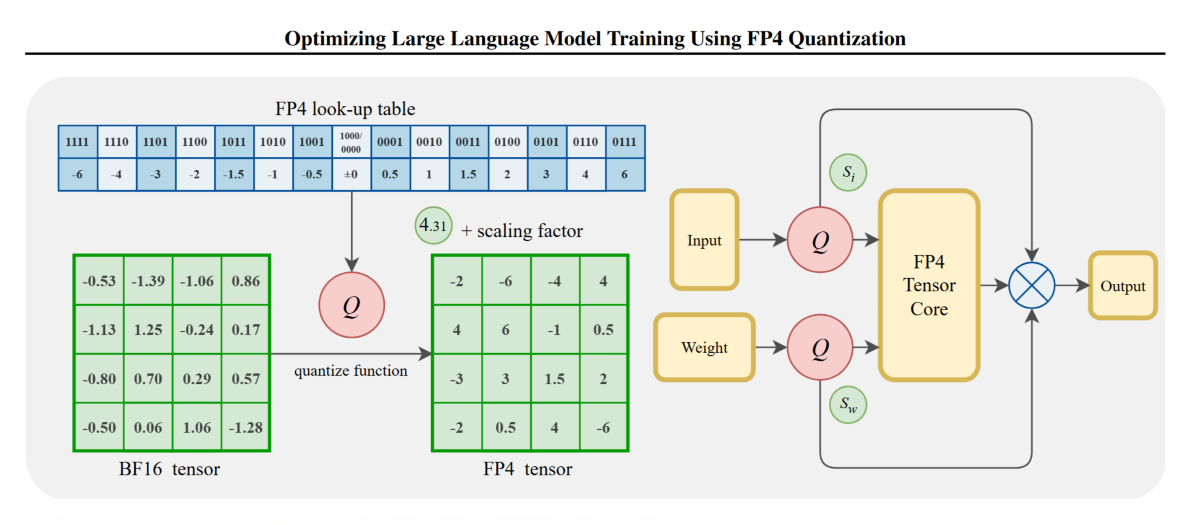
Optimizing Large Language Model Training Using FP4 Quantization
We propose the first FP4 training framework for LLMs, introducing Differentiable Gradient Estimation and Outlier Clamp and Compensation to address quantization challenges, achieving lossless pre-training performance on 13B LLMs and 100B tokens datasets.
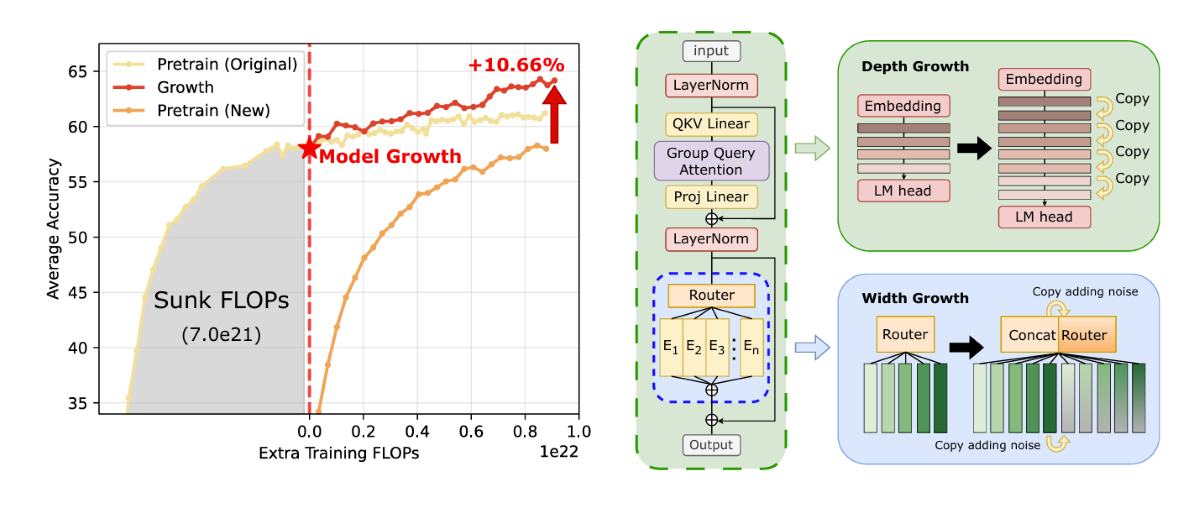
Beyond Sunk Costs: Boosting LLM Pre-training Efficiency via Orthogonal Growth of Mixture-of-Experts
We propose a "checkpoint recycling" strategy that expands existing models through orthogonal growth on 70B MoE models with 1T training tokens, delivering a 10.6% accuracy improvement over training from scratch while significantly maximizing the value of prior computational investments.
📝 Technical Reports
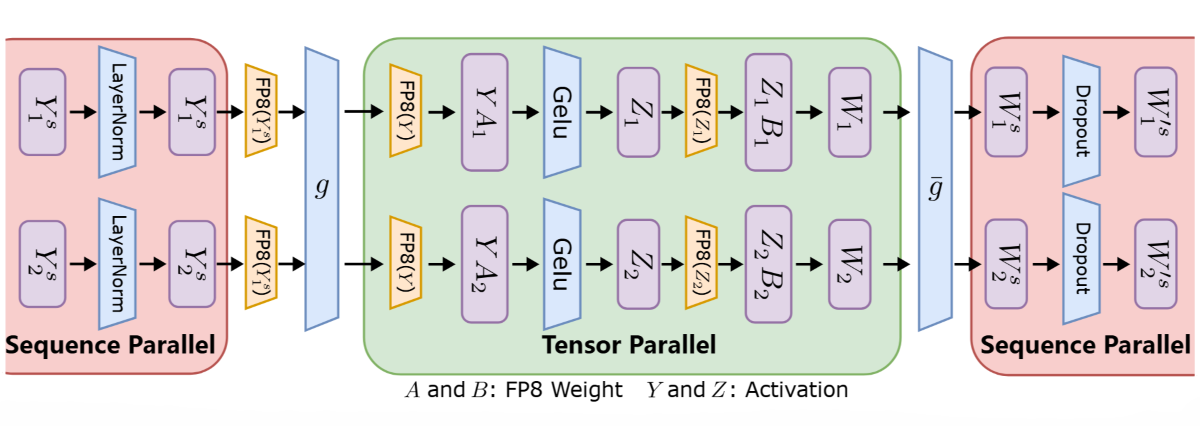
FP8-LM: Training FP8 Large Language Models
A comprehensive FP8 automatic mixed-precision training framework for LLMs that achieves up to 39% reduction in memory usage and 1.75× training speedup on H100 GPUs while maintaining model accuracy comparable to BF16 training.
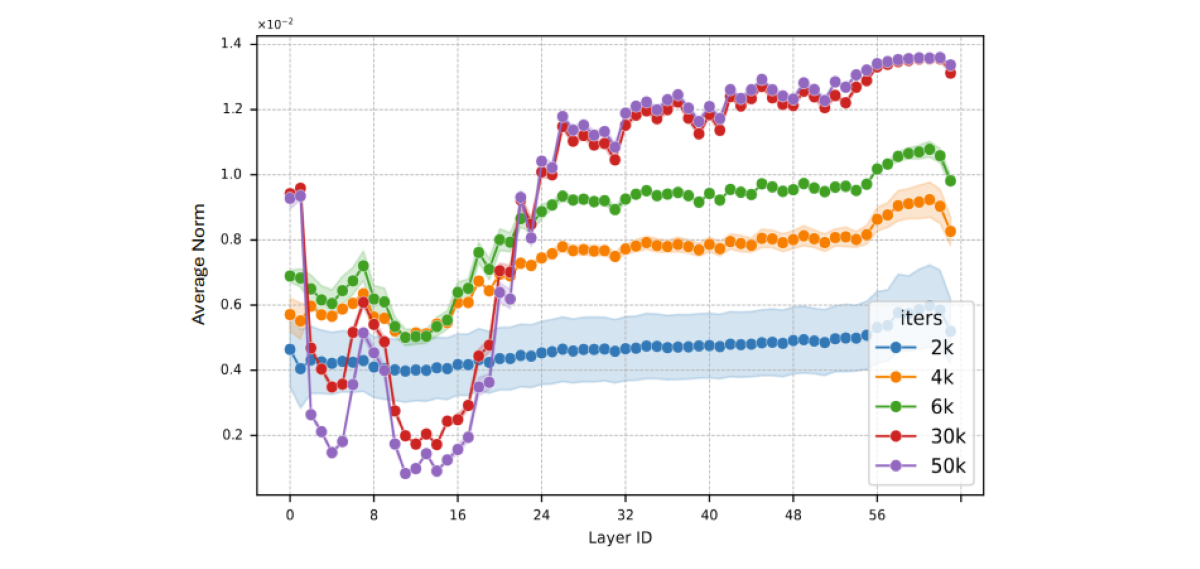
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Introducing SIGMA, an open-source training stack designed to overcome the reliability and efficiency challenges of large-scale AI training on early-life accelerators, enabling the stable pre-training of a 200B MoE model with 94.45% accelerator utilization.
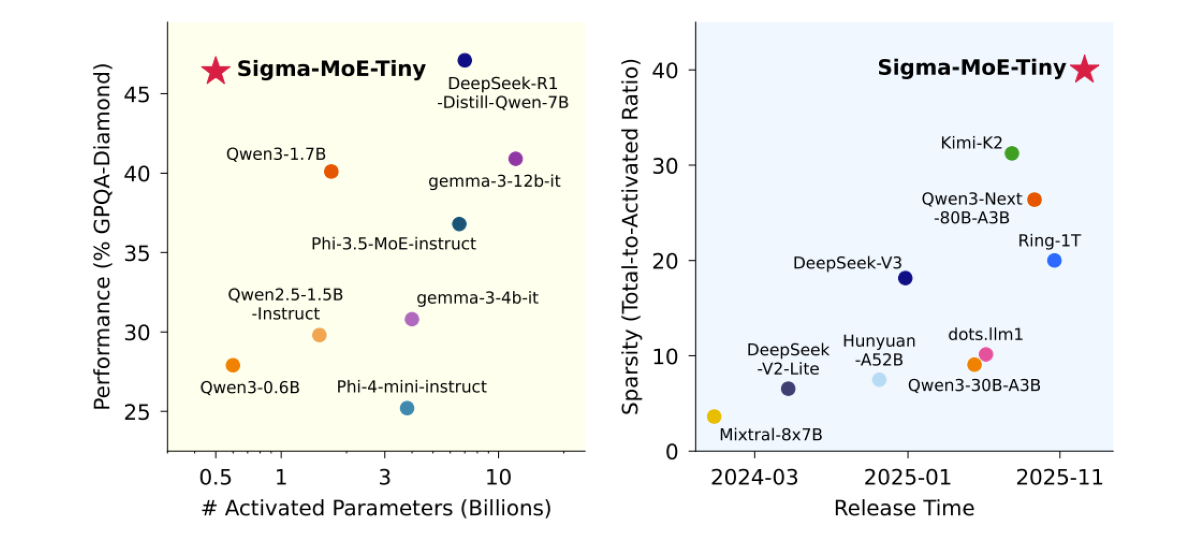
Sigma-MoE-Tiny Technical Report
Introducing Sigma-MoE-Tiny, an ultra-sparse MoE language model that activates only 0.5B out of 20B parameters per token by using a fine-grained 96-expert architecture, achieving state-of-the-art performance at this extreme sparsity.
🦈 Blogs
📚 View full blogs page: All Blog Posts
Stop Wasting Your Pre-trained Checkpoints: Orthogonal Growth Saves You 10%+ Compute
Detailed paper interpretation of "Beyond Sunk Costs: Boosting LLM Pre-training Efficiency via Orthogonal Growth of Mixture-of-Experts" (ICML 2026). This post walks you through the motivation, key insights, and design rationale behind checkpoint recycling for MoE models.
5,000 words Analysis of FP4 Quantization for Training LLMs
Detailed Paper Interpretation of "Optimizing Large Language Model Training Using FP4 Quantization". This post walks you through the motivation, key insights, and design rationale behind our work.
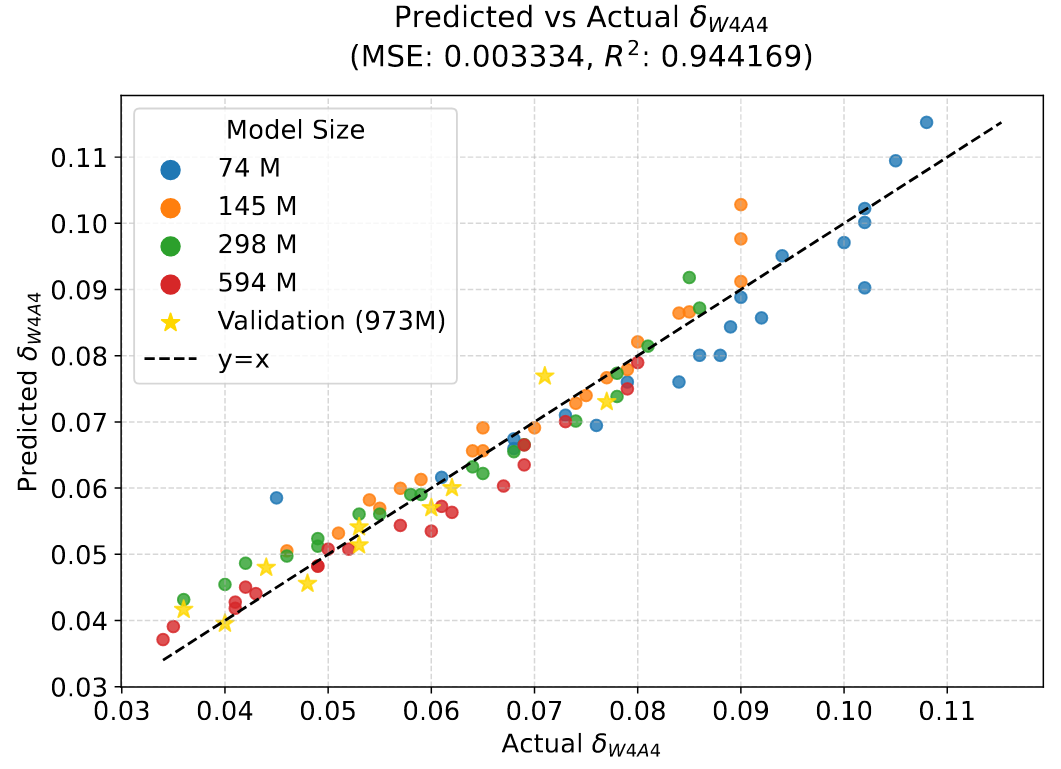
A One-Stop Guide to Scaling Laws in LLM Quantization
A comprehensive overview of Quantization Scaling Laws. Dive deep into 5 papers to understand how performance loss from quantization varies with model parameters and token count.
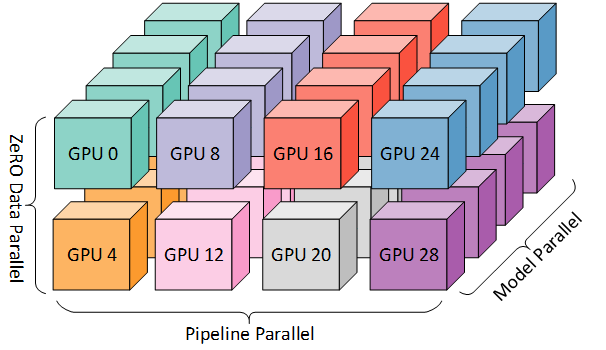
Megatron-LM Training Large Models Practical Guide: 0 - Preface
Why we must use Megatron-LM for large model training, and some warnings for those who have never used it before. A practical guide from personal experience.
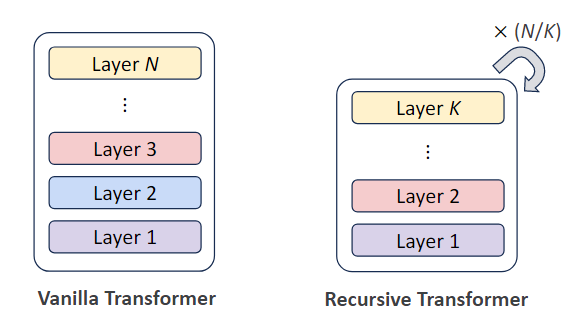
Paper Summary for Recursive Looped Transformers: Parameter Efficiency
Exploring how loops and recursion can improve parameter utilization efficiency in LLMs. A comprehensive summary of recursive mechanisms in Transformer architectures.