| Megaton-LM Training Large Models Practical Guide | 0 - Preface |
Published:
This blog is also available in Chinese version: https://zhuanlan.zhihu.com/p/1959619969617729323
Megaton-LM Training Large Models Practical Guide | 0 - Preface
Colleagues who have worked with large models know well that the code must come before the troops march. Without good code, all research ideas are worthless. In the entire development process of large language models, pre-training is a crucial component. Pre-training code is not difficult per se, but it’s certainly not easy either—small mistakes can render the entire pre-training process futile. In this series of articles, I want to analyze the usage of the Megatron-LM library from a practical perspective, combining some pitfalls I’ve encountered in my own usage to provide an incomplete guide, which also serves as a summary of my own experience.
This is the 0th article of the entire incomplete guide series—preface. It mainly introduces why we must use Megatron-LM, which is actually quite unwieldy, and provides some warnings for those who have never used Megatron-LM before. I believe that if someone who has never used Megatron-LM before directly starts using this library, they will definitely step on a pile of pitfalls and become frustrated (because I myself went through this bumpy journey…).
Clarifying Several Mainstream Concepts
Megatron-LM is a distributed training framework based on PyTorch released by NVIDIA, used for training large language models based on Transformer. Actually, PyTorch itself is already a complete deep learning framework, serving as the foundation for deep learning code. On this basis, Megatron-LM adds many optimization techniques and additional encapsulation to better train large models efficiently on NVIDIA GPUs.
Theoretically speaking, it’s completely feasible to train a model using only PyTorch. However, in practical applications, you might encounter issues such as complex code, low computational efficiency, and inability to train overly large models. Therefore, in most cases, we utilize other more mature higher-level frameworks from the open-source community for model training.
Besides Megatron-LM, there are actually many such higher-level frameworks. The most famous should be the accelerate training framework launched by HuggingFace. The transformer library we know well actually has this training framework as its underlying foundation. The biggest advantage of the accelerate training framework is its high completeness and rich ecosystem, with integration and implementation for almost any deep learning-related task. Besides the large language model training focused on in this article, tasks such as language model fine-tuning, inference, post-training, image understanding and generation, audio/video, multimodal tasks, etc., are basically supported by accelerate. The community is very large, tutorials are complete, and issues and PRs are very active, making it very suitable for beginners or small-scale tasks.
Another one is PyTorch-Lightning, a model training framework proposed by the Lightning-AI team. It essentially also performs high-level encapsulation on PyTorch to make the entire model training process more systematic and standardized. Its advantages include strong reusability, easy maintenance, clear logic, etc. The disadvantages are also obvious—there’s quite a lot of content to learn and understand in this package. Their custom logic is very complex (this point is quite similar to Megatron-LM hhh).
Another relatively well-known one is DeepSpeed developed by Microsoft, but I think it’s not strictly speaking a high-level framework—it’s more like a set of efficient training tools. DeepSpeed is most widely known for introducing the ZeRO (zero redundancy optimizer), combined with CPU-offload technology, which significantly relieves the GPU memory pressure when training large models. In practice, whether using the Megatron-LM framework or the accelerate framework, DeepSpeed technology is sometimes used in conjunction to further optimize GPU memory usage.
There are also frameworks like Fairseq developed by the Meta team and Colossal-AI developed by the hpcai team, among others, which I won’t elaborate on here. It’s clear that the choices for high-level frameworks are quite rich. Among these, the framework I’ve had the most contact with is the Megatron-LM framework. This framework is arguably the most distinctive one I’ve encountered, with very obvious advantages and disadvantages.
Github: NVIDIA/Megatron-LM
github.com/NVIDIA/Megatron-LM
Megatron-LM’s Unique Advantages
Conclusion first: In ultra-large-scale model training scenarios, Megatron-LM is almost the irreplaceable choice.
We all know the importance of computing power in deep learning, especially in pre-training scenarios. As models become larger, the most obvious obstacle is insufficient GPU memory. By default, computers store a number using 32 bits (4 bytes). Taking a model with 1B (10^9) parameters as an example, storing this model requires 4×10^9 bytes, approximately 4GB of GPU memory. As models gradually become larger, the GPU memory needed to store them continues to increase. When this value exceeds the GPU memory limit, training can no longer continue. Clearly, to properly train ultra-large models, a series of techniques to reduce GPU memory usage on individual cards must be adopted.
DeepSpeed’s ZeRO (zero redundancy optimizer) is one such method. It has three levels: stage-1, stage-2, and stage-3, which progressively partition optimizer states, gradients, and model parameters across different GPUs to reduce GPU memory pressure on individual cards. The higher the level, the greater the degree of partitioning, and the smaller the GPU memory pressure each card bears. However, at the same time, the communication pressure between different GPUs becomes greater. In other words, the entire training speed will be slowed down.
According to my testing, ZeRO at stages 1 and 2 is relatively effective, achieving significant memory reduction at smaller communication costs, since optimizer states and gradients only need all-reduce collection during parameter updates. But once the model becomes larger and stage-2 partitioning can’t accommodate it, enabling stage-3 severely slows down training speed. The reason is that once model parameters are also split across different GPUs, the forward and backward computation processes also require substantial communication. Although many techniques can minimize this overhead as much as possible, unfortunately, ZeRO-3 doesn’t optimize speed well enough.
Correspondingly, PyTorch itself has its own version of ZeRO-3—FSDP (Fully Shared Data Parallel). This can be seen as a companion technology to data parallel, where normally when the model isn’t so large that a single GPU can hold the entire model without partitioning, we often use multiple GPUs simultaneously for training. In this case, multi-card parallelism is called data parallel, where each card stores a complete copy of the model, with only the data being different across cards, allowing n sets of data (n being the total number of GPUs) to be processed in the same time. FSDP builds on this by fully chunking the model (Fully Shared) when it’s large, while doing data parallelism. The overall approach is the same as ZeRO-3, but the optimization is better than ZeRO-3.
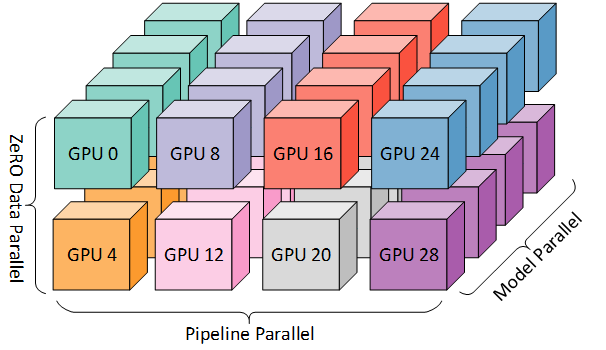
Megatron-LM takes a different approach in model parallelism. Megatron-LM proposes multi-dimensional model parallelism, such as Tensor Parallel, Sequence Parallel (which can be viewed as an extension of tensor parallel), Context Parallel, Pipeline Parallel, and Expert Parallel. In practice, these 5D parallelisms can be organically combined. The impressive aspect is that Megatron-LM’s optimization of this series of model parallelisms is quite good, especially on NVIDIA series GPUs, achieving minimal overall communication overhead through various communication and computation overlap or algorithm-level design. More crucially, due to high parallelism, when it comes to ultra-large models, such as 100B-scale models, Megatron-LM can simultaneously enable parallelism across multiple dimensions, allowing such large models to run in distributed environments with acceptable training speeds.
In practice, the general approach uses Data Parallel (DP) + Tensor Parallel (TP) + Pipeline Parallel (PP). Sequence parallel is usually bundled with tensor parallel, context parallel is only used for long-context training, and expert parallel is specifically for MoE models. The above figure shows a brief illustration of such 3D parallelism (the Model Parallel in the illustration actually represents tensor parallel). Since TP and PP slice the model horizontally and vertically respectively, they can be well combined, with the remaining GPU parallelism used for data parallelism.
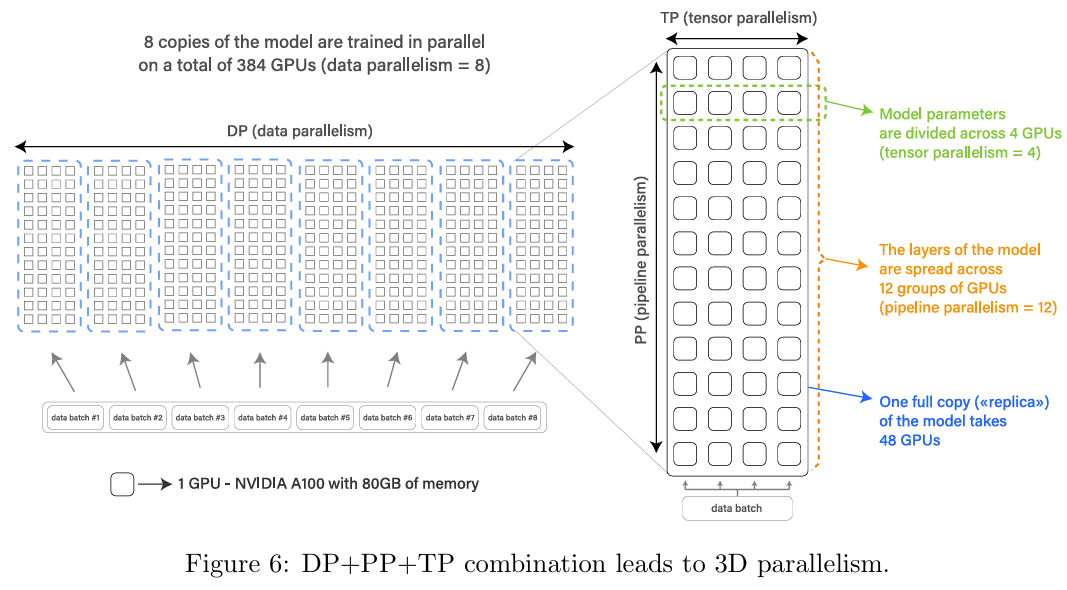
In the Bloom paper (https://arxiv.org/pdf/2211.05100), it detailedly demonstrates which part of the model each card needs to load and which part of data needs to be fed when multiple cards perform high-dimensional model parallelism. For example, within the entire model parallel group, the data on each GPU is identical. However, within the model parallel group, model parameters are partitioned according to TP and PP ranks, with this portion of parameters being different on any GPU within the group. It can be seen that the scheduling of each GPU in this process is very complex. Megatron-LM’s encapsulation and processing in this area is already very complete—users only need to specify the size of different dimensional model parallelism in advance, and the code will automatically handle the scheduling of various data and model parameters.
For example, for a 200B model, at least 128 GPUs with 80GB memory are needed, which means slicing the model into 128 pieces, with each piece loaded into each GPU to enable normal training. This is because during model training, the GPU memory doesn’t just need to store the model, but also gradients, momentum (collectively called optimizer states), activation values, and some cache. In such an extreme multi-machine parallel scenario, only Megatron-LM’s implementation can guarantee that training still has certain efficiency. If using some poor implementations for model parallelism, it might take several minutes to train one step, which is completely unacceptable.
Besides high model parallelism, Megatron-LM also has other advantages for large language model training, including distributed checkpoint storage, activation checkpoint storage to save memory, native support for Transformer Engine, H-series and B-series GPU adaptation, FP8 training, etc. However, more often than not, Megatron-LM feels like a choice that must be used when there’s no other option for training large models. After all, from an engineering perspective, Megatron-LM is really not user-friendly. Moreover, there has always been feedback in the open-source community about precision issues with Megatron-LM’s communication implementation. During my use of Megatron-LM, I also felt the deep malice of this library.
Megatron-LM Pitfalls Summary
1. Sick Code
The most uncomfortable aspect of Megatron-LM is the organization of the entire training code architecture. Pick any random file, and you’ll find functions constantly importing each other, with layers upon layers of imports that take forever to trace. Take pretrain_gpt.py, the main training entry function, for example. Either expose a single interface for users to start training, or provide a complete training loop including load model, forward, backward, etc. But can you believe that this file only defines a pretrain() function in the main interface, writes the main training loop in core/training.py, but puts the definitions of loss_function and forward_step, and even get_batch functions back in the pretrain_gpt.py training main entry file? It’s completely incomprehensible, though it does run normally. Even more abstract is that this main file also has train_valid_test_datasets_provider, which actually just calls another dataset builder function. It’s strange why this call is written separately here, with multiple nested calls… There are too many complaints to list one by one.
Although I’ve now completely gotten used to Megatron-LM’s code organization, I’m sure first-time viewers will be completely confused. Their README is also a mess, but fortunately, about two months ago they finally had a change of heart and updated the README, providing the project’s code structure, which is slightly clearer now.
Megatron-LM/
├── megatron/
│ ├── core/ # Megatron Core (kernels, parallelism, building blocks)
│ │ ├── models/ # Transformer models
│ │ ├── transformer/ # Transformer building blocks
│ │ ├── tensor_parallel/ # Tensor parallelism
│ │ ├── pipeline_parallel/ # Pipeline parallelism
│ │ ├── distributed/ # Distributed training (FSDP, DDP)
│ │ ├── optimizer/ # Optimizers
│ │ ├── datasets/ # Dataset loaders
│ │ ├── inference/ # Inference engines
│ │ └── export/ # Model export (e.g. TensorRT-LLM)
│ ├── training/ # Training scripts
│ ├── inference/ # Inference server
│ ├── legacy/ # Legacy components
│ └── post_training/ # Post-training (RLHF, etc.)
├── examples/ # Ready-to-use training examples
├── tools/ # Utility tools
├── tests/ # Comprehensive test suite
└── docs/ # Documentation
2. Completely Absent Open Source Ecosystem
As everyone knows, for an open-source library, users generally ask questions or make contributions through Issues or Pull Requests. But with Megatron-LM, Issues are basically useless, PRs are completely ignored. If you encounter any problems during development, you’re unlikely to find answers here. The entire development team seems to be in a “solitary enjoyment” state. The whole issue interface is messy and worthless, with many ancient issues transferred to discussions by administrators without any follow-up.
As for tutorials and documentation, there are some, but they’re almost useless. The official User Guide is very brief and hardly helps you at all. Only the API Guide can provide some API usage methods, but there are also some outdated APIs that no one updates. I even found an error in their official User Guide and submitted a PR, which even got two people reacting with thumbs up. It was just a simple problem, but zero people responded, and I eventually closed it myself hhh.
[BUG FIX] Fix world_size bug in QuickStart Example #747 github.com/NVIDIA/Megatron-LM/pull/747
### 3. Volatile Version Updates One shocking aspect of Megatron-LM is that the main branch has commits almost daily. It could just be fixing a few typos, but they’re freshly committed into main (I’ve actually found this). This completely violates the development standards of a major open-source library, making it almost impossible for users to track important version updates, including important bug fixes or major new feature releases. It’s possible that code versions that worked last month might have bugs this month, which is very fatal for users.
I myself stepped on a big pit here. It should have been around mid-2024 when Megatron released several major version updates. The most critical change was that it replaced almost all APIs, including file locations, function names, parameter passing, and even many code logic changes. This caused my previously modified Megatron based on the old API version to be incompatible with the new version, making many new features like MoE support and distributed checkpoint support unusable. It was really frustrating at the time but there was no choice—re-modifying on the new API version would be too costly.
Therefore, I strongly recommend not to directly fork the main branch for development. At least choose a recent stable version. When you want to upgrade your own Megatron version, be sure to diff carefully to see if there are major code changes to prevent your long-used code from breaking directly.
4. Numerous Hidden Bugs, Both Algorithmic and Engineering Practice Issues
The pitfalls I’ve encountered are very detailed, but most are not particularly fatal. They may be explained in detail later in several articles involving specific aspects such as data processing and model loading. The Zhihu community also has many colleagues who have carefully analyzed some bugs in Megatron-LM. Some algorithmic bugs might be quite fatal—I previously read an article about ring-allreduce communication calculation precision being insufficient, causing training to fail to converge.
Thoughts triggered by InternLM-7B failing to converge when trained on A800 platform
https://zhuanlan.zhihu.com/p/701623664
2052 Upvotes · 84 Comments Article
Let’s take a look at the pitfalls and optimization points of Nvidia’s large-scale distributed training framework Megatron-LM?
https://www.zhihu.com/question/633778272/answer/8254591489
197 Upvotes · 37 Comments Answer
It’s not that you must use Megatron-LM
Nvidia has a library called NeMo, developed by a different team than Megatron-LM, but similar to Megatron-LM. It should be an additional layer of encapsulation on top of Megatron-LM, but its open-source community ecosystem and tutorials completely surpass Megatron-LM, and it has added much support for multimodal tasks like audio and images.
Github: NVIDIA-NeMo/NeMo
github.com/NVIDIA-NeMo/NeMo
In addition, I recently observed on Zhihu a training framework called torchtitan developed natively by PyTorch that looks quite promising. The open-source community ecosystem is guaranteed, it supports multi-dimensional model parallelism, and it has put considerable effort into mixed-precision training. Perhaps the only disadvantage is that this framework is still in its early stages, and we need to see how it performs in practical scenarios.
Github: pytorch/torchtitan
github.com/pytorch/torchtitan
Summary
If you’re like me before, exploring the Megatron-LM library from scratch, I hope the pitfalls I’ve encountered can help you. I will also go into specific stages of training large models and summarize the basic logic of using Megatron-LM in detail, including data preparation, modifying model structure, parameter adjustment, checkpoint storage and evaluation, etc. Stay tuned!