
Megatron-LM 3 posts


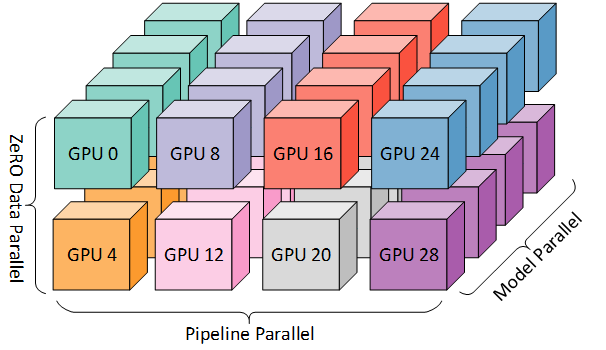
Paper Interpretation 4 posts
Paper Summary for Recursive Looped Transformers: Latent Reasoning
A paper-reading note on latent reasoning in Looped / Recursive Transformers: scaling test-time compute via recurrent depth, recursive latent thoughts, and large-scale looped language models.
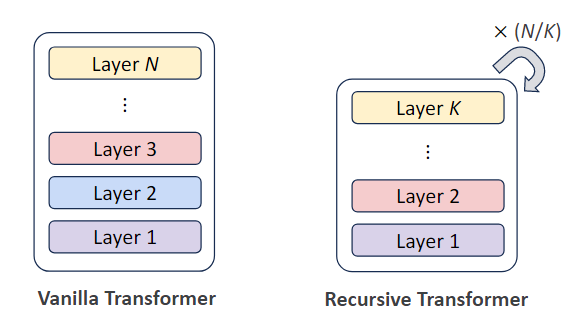
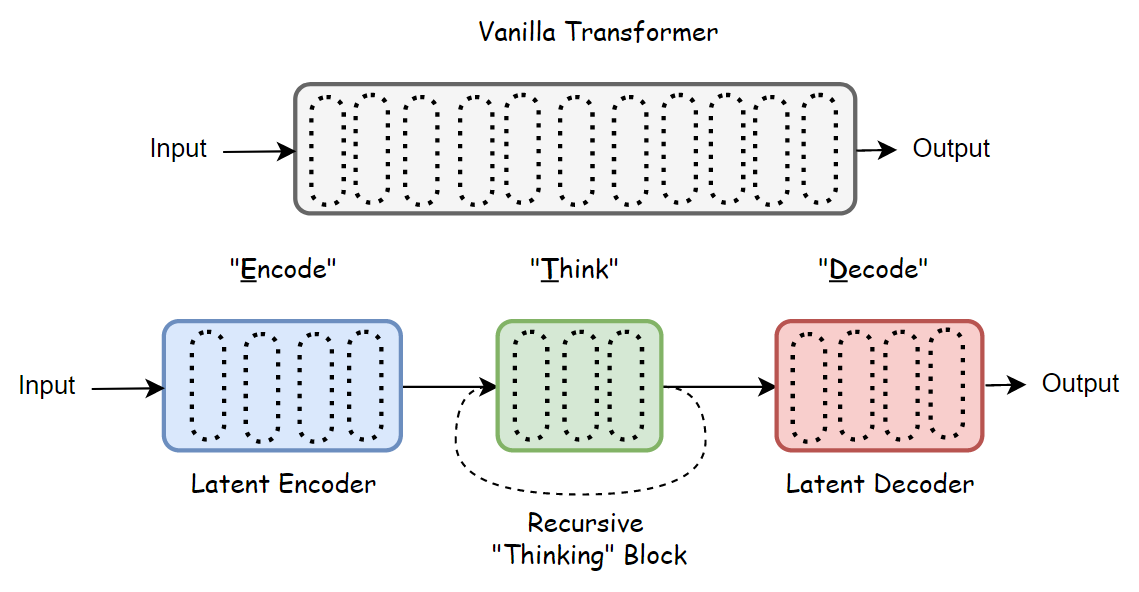
Paper Summary for Recursive Looped Transformers: Parameter Efficiency
Exploring how loops and recursion can improve parameter utilization efficiency in LLMs. A comprehensive summary of recursive mechanisms in Transformer architectures.
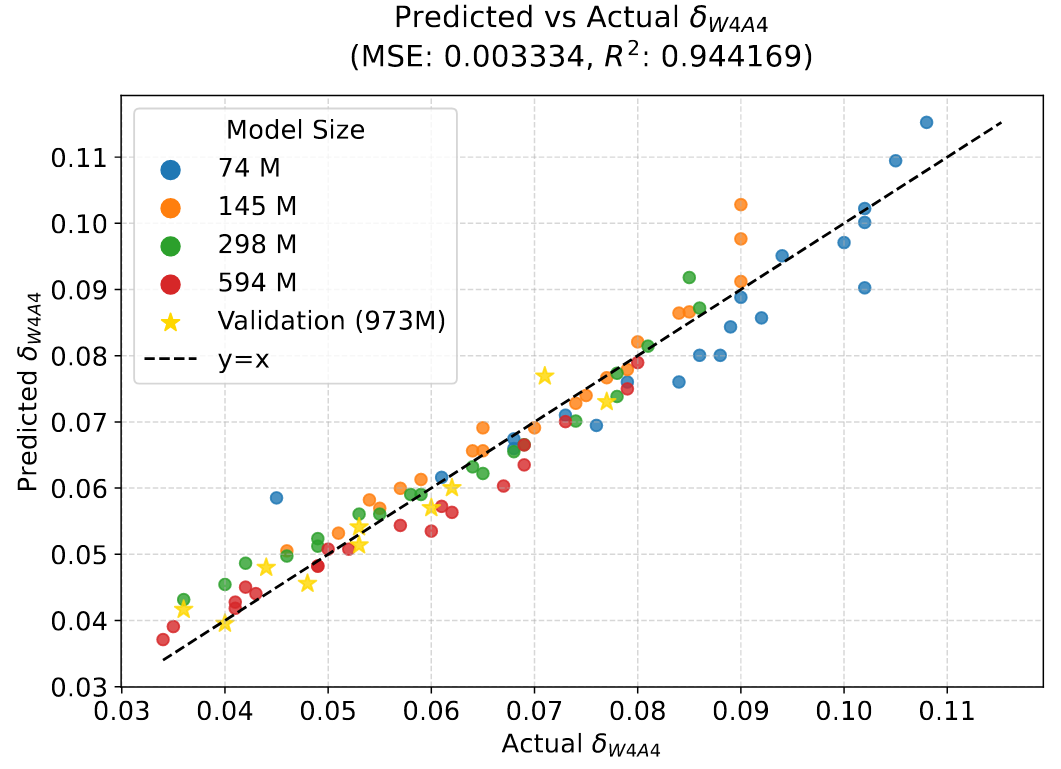
A One-Stop Guide to Scaling Laws in LLM Quantization
A comprehensive overview of Quantization Scaling Laws. Dive deep into 5 papers to understand how performance loss from quantization varies with model parameters and token count.
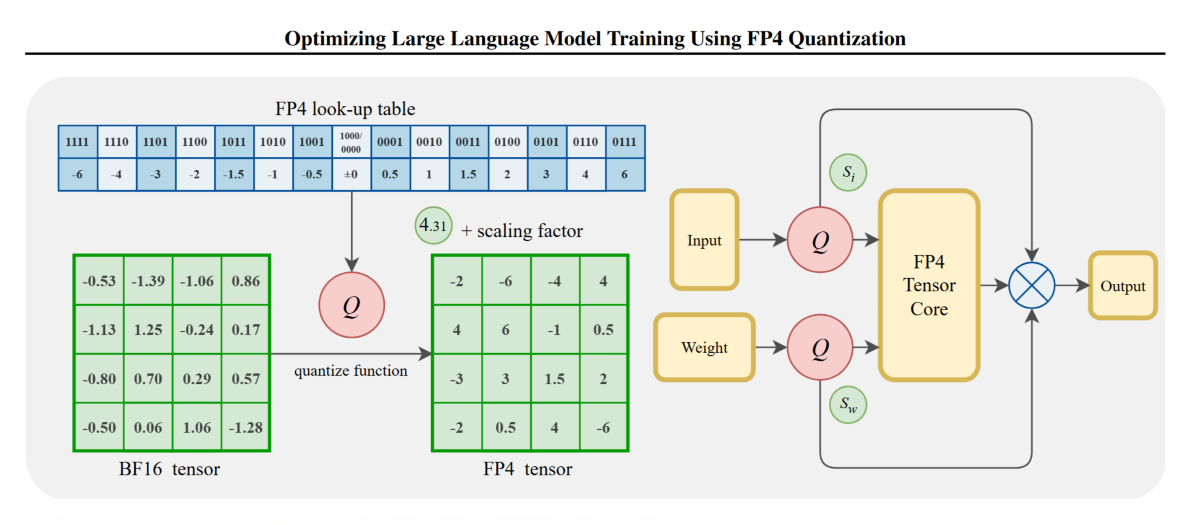
5,000 words Analysis of FP4 Quantization for Training Large Language Models
Detailed Paper Interpretation of ‘Optimizing Large Language Model Training Using FP4 Quantization’. This post walks you through the motivation, key insights, and design rationale behind our work.
Practical Guide 3 posts
Quantization 2 posts
A One-Stop Guide to Scaling Laws in LLM Quantization
A comprehensive overview of Quantization Scaling Laws. Dive deep into 5 papers to understand how performance loss from quantization varies with model parameters and token count.
5,000 words Analysis of FP4 Quantization for Training Large Language Models
Detailed Paper Interpretation of ‘Optimizing Large Language Model Training Using FP4 Quantization’. This post walks you through the motivation, key insights, and design rationale behind our work.
Recursive Transformers 2 posts
Paper Summary for Recursive Looped Transformers: Latent Reasoning
A paper-reading note on latent reasoning in Looped / Recursive Transformers: scaling test-time compute via recurrent depth, recursive latent thoughts, and large-scale looped language models.
Paper Summary for Recursive Looped Transformers: Parameter Efficiency
Exploring how loops and recursion can improve parameter utilization efficiency in LLMs. A comprehensive summary of recursive mechanisms in Transformer architectures.